|
| |
Allgemeines
Grundlagen
Gemäß eines Beschlusses des IT-Planungsrates und der Innenministerkonferenz „Lateinische
Zeichen in Unicode, Version 1.1 vom 27.1.2012“ (auch „String.Latin 1.1“
genannt) müssen Softwaresysteme, die dem Länder übergreifenden Austausch von
Personen- und Adressdaten dienen eine definierten Zeichenvorrat handhaben
können.
Als Weiterentwicklung dazu wurde März 2019 die DIN SPEC 91379:2019-03
verabschiedet zur Definition von "Unicode für die elektronische Verarbeitung
von Namen und den Datenaustausch in Europa"
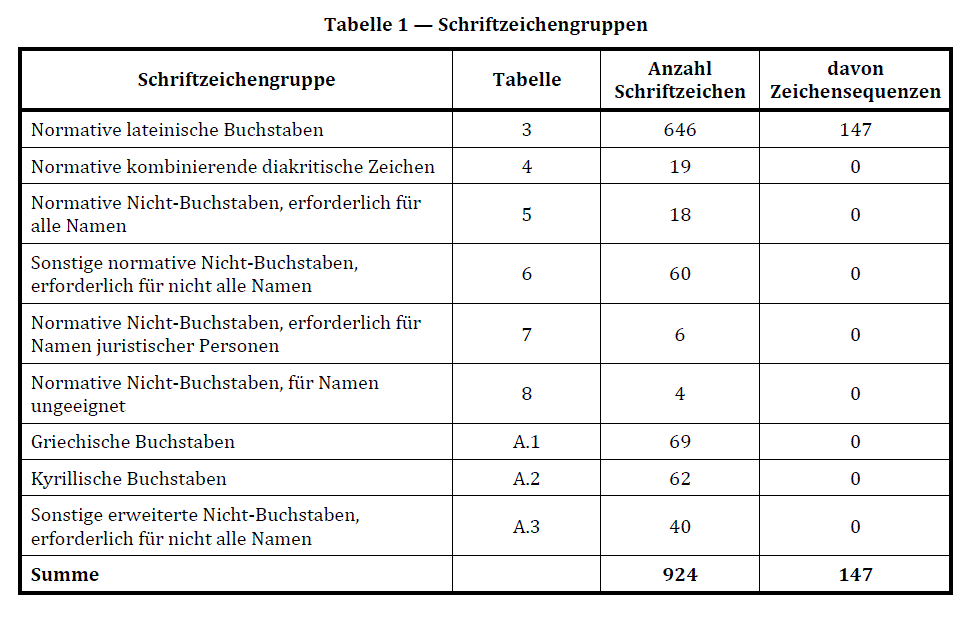
Schriftzeichengruppe
In der DIN SPEC 91379 werden Schriftzeichengruppe als Zusammenfassung von
Schriftzeichen unter fachlichen Aspekten festgelegt.
 | Normative Schriftzeichen
 | Tabelle 3: Normative lateinische Buchstaben (netto, ohne Kombination
mit diakritische Zeichen) |
| Tabelle 5 (N1): Normative Nicht-Buchstaben, erforderlich für alle
Namen |
| Tabelle 6 (N2): Sonstige normative Nicht-Buchstaben, erforderlich
für nicht alle Namen |
| Tabelle 7 (N3): Normative Nicht-Buchstaben, erforderlich für Namen
juristischer Personen |
| Tabelle 8 (N4): Normative Nicht-Buchstaben, für Namen ungeeignet |
|
| Erweiterte Schriftzeichen (nicht-normativ)
| A.1 Griechische Buchstaben |
| A.2 Kyrillische Buchstaben |
| A.3 Sonstige erweiterte Nicht-Buchstaben, erforderlich für nicht
alle Namen |
|
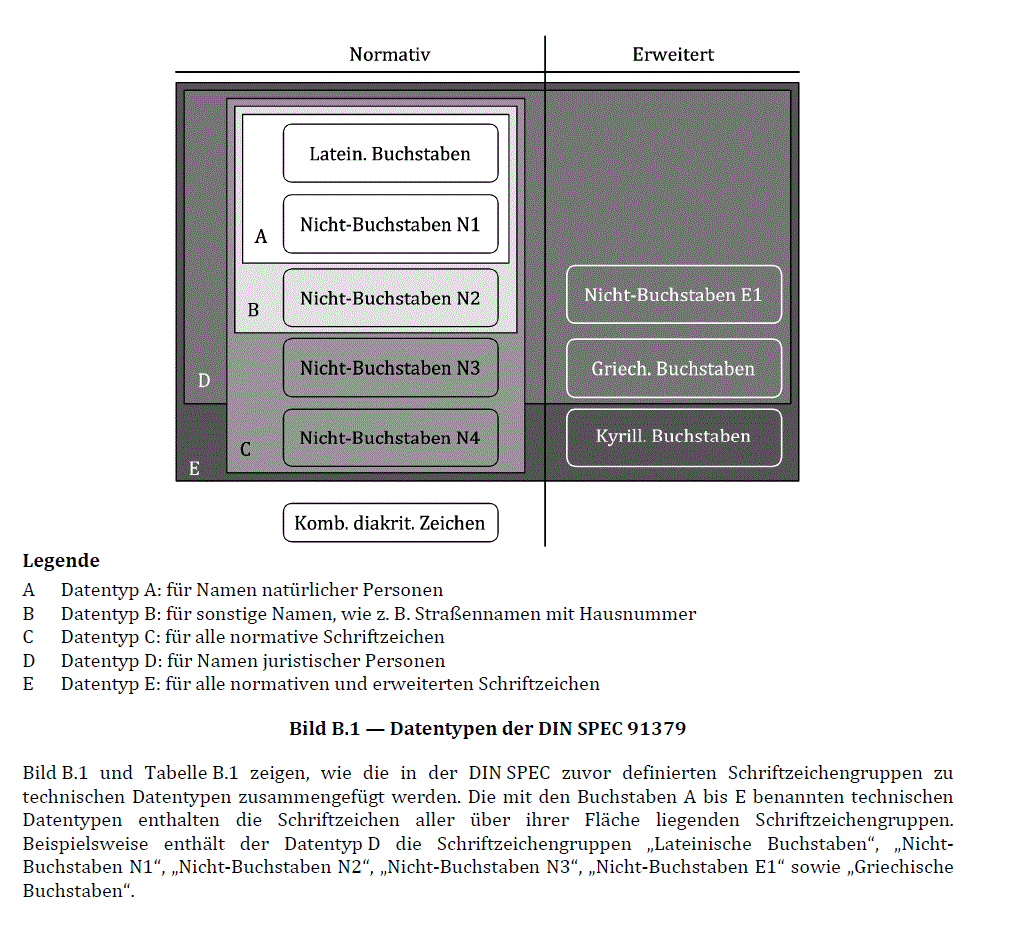
Datentypen und zugehörige Schriftzeichengruppe
Gemäß DIN SPEC gilt es folgende 5 Datentypen zu unterscheiden
Datentyp A: Namen natürlicher Personen
| Der Datentyp A gibt wieder, welche Schriftzeichen in hoheitlichen
Dokumenten für Namen natürlicher Personen verwendet werden. |
| Datentyp A ist definiert durch
| die abschließenden Listen aller lateinischen Buchstaben nach Tabelle
3 |
| und der für alle Namen erforderlichen Nicht-Buchstaben nach Tabelle
5. |
| Andere Schriftzeichen werden durch diesen Datentyp zurückgewiesen. |
|
Datentyp B: sonstige Namen
| Der Datentyp B wurde vor allem für sonstige Namen, wie z. B. Ortsnamen
und Straßennamen mit Hausnummer, entworfen. |
| Datentyp B ist definiert durch
| die abschließenden Listen aller lateinischen Buchstaben nach Tabelle
3, |
| der für alle Namen erforderlichen Nicht-Buchstaben nach Tabelle 5
|
| und der sonstigen normativen Nicht-Buchstaben nach Tabelle 6. |
| Andere Schriftzeichen werden durch diesen Datentyp zurückgewiesen.
|
|
Datentyp C: Alle nach DIN SPEC 91379 normativen Schriftzeichen
| Der Datentyp C wurde für alle normativen Schriftzeichen der DIN SPEC
entworfen.
| Er ist somit die technische Umsetzung der Schnittstellenvereinbarung
„Alle nach DIN SPEC 91379 normativen Schriftzeichen“. |
| Texte mit griechischen oder kyrillischen Buchstaben oder mit
erweiterten (nicht-normativen) Nicht-Buchstaben sind unzulässig. |
|
| Datentyp C ist definiert durch
| die abschließenden Listen aller lateinischen Buchstaben nach Tabelle
3, der für alle Namen erforderlichen |
| Nicht-Buchstaben nach Tabelle 5, |
| der sonstigen normativen Nicht-Buchstaben nach Tabelle 6, |
| der normativen Nicht-Buchstaben, erforderlich für Namen juristischer
Personen nach Tabelle 7 |
| und der normativen für Namen ungeeigneten Nicht-Buchstaben nach
Tabelle 8. |
| Andere Schriftzeichen werden durch diesen Datentyp zurückgewiesen. |
|
Datentyp D: Namen juristischer Personen und für Produktnamen
| Der Datentyp D wurde vor allem für Namen juristischer Personen und für
Produktnamen entworfen. |
| Datentyp D ist definiert
| durch die abschließenden Listen aller lateinischen Buchstaben nach
Tabellen 3 |
| und griechischen Buchstaben nach Tabellen A.1, |
| der für alle Namen erforderlichen Nicht-Buchstaben nach Tabelle 5
|
| sowie der für Namen (im weiteren Sinne) geeigneten normativen und
erweiterten Nicht-Buchstaben nach den Tabellen 6, 7 und A.3. |
| Andere Schriftzeichen werden durch diesen Datentyp zurückgewiesen. |
|
Datentyp E: Alle nach DIN SPEC 91379 normativen und nicht-normativen
Schriftzeichen
| Der Datentyp E wurde für alle normativen und erweiterten Schriftzeichen
der DIN SPEC entworfen.
| Ein Einsatzgebiet dieses Datentyps kann der grenzüberschreitende
Datenaustausch sein, wenn auch griechische und kyrillische Buchstaben
benötigt werden. |
| Er ist somit die technische Umsetzung der Schnittstellenvereinbarung
„Alle nach DIN SPEC 91379 normativen und nicht-normativen
Schriftzeichen“. |
| Texte mit Buchstaben oder Nicht-Buchstaben, die in der DIN SPEC
nicht enthalten sind, wie z. B. asiatische oder arabische Buchstaben,
sind unzulässig. |
|
| Datentyp E ist definiert durch
| die abschließenden Listen aller lateinischen, griechischen und
kyrillischen Buchstaben nach den Tabellen 3, A.1 und A.2 |
| sowie aller normativen und erweiterten Nicht-Buchstaben nach den
Tabellen 5, 6, 7, 8 und A.3. |
| Andere Schriftzeichen werden durch diesen Datentyp zurückgewiesen. |
|
Übersicht Datentypen
Datentypen und Verwendung
Lateinische Zeichen in Unicode in HIT
| Seit Mitte 2020 ist in HIT/ZID die Übertragung von Lateinische Zeichen
in Unicode gemäß "Datentyp E: Alle nach DIN SPEC 91379 normativen und
nicht-normativen Schriftzeichen" realisiert. |
| Welche Untermenge davon im jeweiligen fachlichen Kontext sinnvoll und
erlaubt ist muss innerhalb der fachlichen Vorgaben für die Teilverfahren
festgelegt werden und ist nicht Bestandteil der technischen Umsetzung. |
HIT-Protokoll
| Eine Änderung im HIT-Protokoll selbst ist nicht notwendig. |
| Es genügt wenn der Client das HIT-Protokoll
| in Unicode UTF-8 kodiert auf dem Socket verwendet |
| bzw. vor und nach der Verschlüsselung entsprechend kodiert und
dekodiert, nähere Hinweise hier bei
HIT-Verschlüsselung ... |
| dem Server im ersten Befehl - dem LOGON dies mittels Parameter
mitteilt |
| Ein Wechsel des Zeichensatzes bzw. der Zeichensatzkodierung
innerhalb einer aufgebauten Verbindung ist nicht möglich. |
|
HIT-Batch
| Der HitBach-Client kann seit 2020 entsprechend in Unicode UTF-8 mit dem
Server kommunizieren. |
| Dazu sind lediglich in der HitBatch.INI im Kapitel [Global] Parameter
folgendermaßen zu setzen
| StreamEncodingIn=UTF-8 |
| StreamEncodingOut=UTF-8 |
| UTF8=1 (beachte: hier ohne
Strich) |
|
| Um den vollen Zeichenumfang nutzen zu können müssen die
Input/Outputdateien entsprechend kodiert sein. Gesteuert wird das mit den
Parametern InFileCharset bzw.
OutFileCharset |
| Weitere Details siehe HitBatch INI-Parameter
|
HIT/ZID Oberflächen
Neue Weboberflächen / Meldeprogramme
| HIT V.3 - neues HIT Meldeprogramm |
| ZID V.2 - neues ZID Meldeprogramm |
In den neuen Programmen werden die HTML-Seiten/Formulare UTF-8 kodiert
ausgegeben und eingelesen, Damit werden alle relevanten Unicode Zeichen richtig
dargestellt und entgegengenommen.
Bei den Suchfunktionen werden zur Zeit keine der von der DIN SPEC
vorgeschlagenen "Gleichsetzungen" vorgenommen. Sonderzeichen werden nur exakt so
gesucht wie sie im Suchkriterium angegeben sind.
Alte Weboberflächen / Meldeprogramme
| HIT V.1 - klassisches HIT Meldeprogramm |
| HIT V.2 - REST Version 1 besitzt nur eine Testoberfläche |
| ZID V.1 - altes ZID Meldeprogramm, dient nur noch zur Anzeige
historischer Daten und wird von Endkunden nicht mehr benutzt. |
In den alten Programm wird keine Anpassung vorgenommen. Eingaben und Ausgaben
sind nach wie vor nur in ISO / ANSI möglich. Geringfügige Darstellungsprobleme
von nicht westeuropäischen Zeichen oder Sonderzeichen müssen akzeptiert werden,
haben aber auf die Funktionsfähigkeit keine Auswirkung. |

