|
 |
|
|
|
|
AllgemeinFür systematische Test auf Meldungen und ähnlichem verwendet die Zentrale Datenbank (ZD) ein mit JUnit geschriebenes Framework namens Javatest. Dieses basiert auf Befehlen, die zum einen Aktionen auf der Datenbank auslösen (per HIT-Protokoll-Befehlen) und die zum anderen Prüfungen auf Gültigkeiten durchführen. Zudem sind einfache Schleifen und Variablenarithmetik möglich. Für die Anwendung des Programms außerhalb der ZD wurde das Programm leicht
modifiziert und kann daher ohne direkte Datenbankverbindung arbeiten. Da
systematische Tests regelmäßig laufen sollen, wenn Änderungen an der
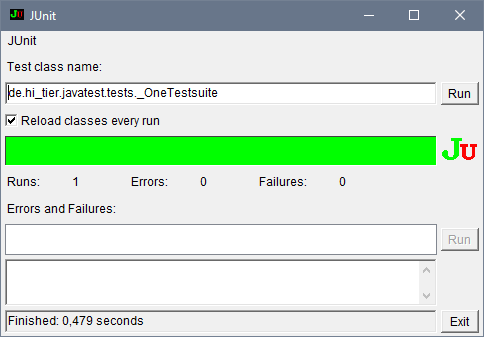
Anwendung durchgeführt wurden, darf der Javatest physikalische Download: HitJavatest.zip (2.6 MB vom 20.01.2023) Das Archiv enthält benötigte JAR-Dateien, ein Aufrufscript samt Beispiel-Datendateien und eine ausführliche Anleitung im HTML-Format. Nach dem Start (Batchscript
Läuft der Test fehlerfrei durch, erscheint ein grüner Balken. Ging etwas schief,
ist er rot und im Logfile (in Ini-Datei bei Man kann durch Klicken auf (das obere) "Run" den Test (z.B. nach Änderung an Testdatei) mehrmals neu starten, jedoch wird das Ergebnis in der Ausgabedatei immer angehängt, so dass das Ergebnis dann mehrfach in der Ausgabedatei steht. Anfang 2021 wurden die Javapakete umstruktriert, d.h. der frühere Aufruf von
JUnit mit
|
|
|